
生成AIを活用するなかでは、自社や各部署のルールに沿った対応ができるよう設定したいと思うことが多いでしょう。このニーズに対応できるものがRAG(検索拡張生成)です。生成AIが知識を習得するには、人間側が資料やデータを提供するなどの追加学習を行う方法が一般的ですが、RAGの活用によって手軽に情報を学習させることが可能です。
この記事ではRAGの概要と仕組みをはじめ、メリットや活用例、注意点について解説します。RAGについて理解を深め、業務の効率化を実現・促進させましょう。

生成AI活用におけるRAGとは
RAGとは、機械学習のひとつである大規模言語モデル(LLM)の回答精度を高めるための技術のことで、検索機能と生成機能を組み合わせた特徴により日本語では「検索拡張生成」と訳されています。
LLMが学習データに追加する形で外部のデータベース・検索エンジンから情報を取得し、得た情報を元に回答を生成するため、高精度かつ最新情報に基づく回答を実現します。つまり、生成AIの活用にあたってはRAGの活用が望ましく、利活用によって自社に点在するさまざまな業務の効率化を実現・加速することが可能です。
RAGが必要とされる理由
RAGが必要とされる理由には、以下のような項目が挙げられます。
- ハルシネーションの抑制
- 非公開情報の利用
- 根拠の明示
現在の生成AIは、学習データに基づき「もっともらしい情報」を生成する特性を持っています。「もっともらしい情報」とは、事実に基づかない情報や虚偽の内容を指し、正確性に長けた情報を生成するだけでなく、誤った情報までも作り出してしまう危険性があるということです。
ビジネスで生成AIを利活用する場合、正確な情報が欠かせません。RAGを活用すると、信頼できる情報源から関連性の高い情報を集め、それらを元にデータを生成できます。
また、正確な情報を取得するためには検索エンジンでは検索・閲覧できない非公開情報をはじめ最新の独自データが必要になる状況がありますが、RAGによってこれらの情報も取得し生成AIに学ばせることができます。
その結果、従来と比べて正確性に優れた情報をビジネスシーンで利活用できるようになるほか根拠も明示されるため、生成された情報の信頼性を高めることが可能です。
生成AIの課題
生成AIの利活用においては、いくつかの課題があることを念頭に置く必要があります。先述したようにハルシネーションによって虚偽の情報であるにもかかわらず、その情報を「もっともらしく」生成することがあります。そのため、独自のルールに基づいて作動させるためには、事前にルールについて理解させる必要があります。
生成AIは万能のように見えますが、できないことや不得意とすることもあります。そのため、ビジネスに生成Aを利活用する場合には、RAGを使いながら生成AIそのものの精度向上を図り、自社ルールに順応させていくことが大切です。
関連記事:生成AIにできること・できないことを徹底解説|今すぐ使える活用例も紹介
RAGが作動する仕組み
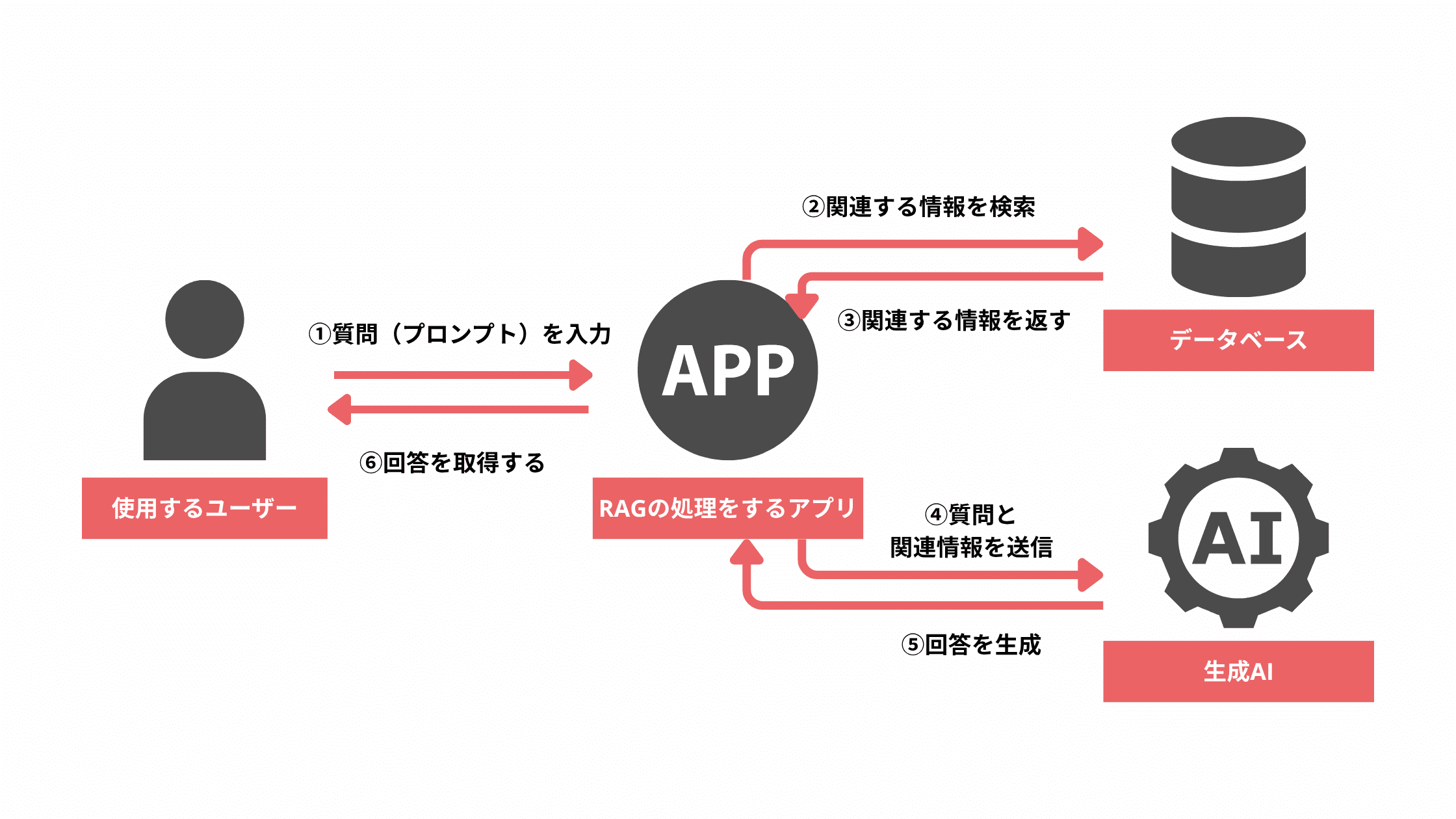
社内用生成AIにRAGを利用するプロセスは下記の通りです。
必要資料・情報を準備する
まずは社内規程に関する資料・データを準備しましょう。用意したデータを格納し検索用データベースの構築が終わったら、次に従業員の質問内容に紐付く独自情報を抽出できるよう、検索機能を用意します。
このとき、従業員からの質問を集め、検索用データベースと生成AIを連携させ、RAG処理を実現するためのアプリケーションも用意しておきましょう。
質問(プロンプト)を入力する
あらかじめ構築されたアプリケーションに対し、従業員は質問(プロンプト)を入力します。例えば「商品Aを100万円分発注しようと検討中だが、誰の決裁を取得する必要があるか」などです。プロンプトに迷ったときは、従業員から集めた質問内容を参考に入力してみるとよいでしょう。
情報を取得する
アプリケーションが入力した質問に対して適切に回答できるよう、必要な情報を取得します。前項の質問に必要な資料であれば、企業の権限規程が適しています。
回答を生成する
アプリケーションでは、従業員が入力した質問と検索用データベースから収集した情報を組み合わせて生成AIに生成させます。そのため、取得した権限規程の情報を盛り込んだ場合「商品Aを発注する場合は部長の決裁が必要です」といった回答を生成AIから取得できます。
RAGの精度を上げる!10種の有効な方法
RAGの精度が高いほど、ビジネスシーンで多用できる生成AIへと近づけられます。ここからはRAGの精度を上げる10種の有効な方法について解説します。
1.プロンプトエンジニアリングの最適化
RAGの精度を上げるためにはプロンプトの見直しが欠かせません。このようなときは、プロンプトエンジニアリングの最適化を図りましょう。プロンプトエンジニアリングとは大規模言語モデルから最適なデータを出力するため、指示・質問を設計・最適化する技術のことで、AIに何をさせたいのかをより明確に伝えることができます。
例えば「取得したデータに基づいて回答してください」「取得したデータにない質問に対しては『わからない』と答えるようにしてください」のように具体的な指示を与えることでハルシネーションの抑制や生成データの信頼性向上につながります。
2.参照元データの拡充と質の向上
RAGは外部の知識ベースから情報を検索し大規模言語モデルの知識を補うため、参照できるデータ量と品質がそのままRAGシステムの性能に直結します。これらのことから、RAGから抽出する回答領域を必要な情報で補完する、十分なデータ量をそろえることが大切です。
特に、組織など限定的なテーマに関する質問が多い場合は、自社の権限規程をはじめ、業務マニュアルなどを積極的に追加すると範囲の広い質問にも対応できるようになります。
3.チャンクサイズの最適化
チャンクサイズとはデータを処理・保存するために分割する場合の単位の大きさのことです。大規模言語モデルにはコンテキストウィンドウと呼ばれる入力トークン数に上限があり、RAGが取得した大量のデータをそのまま渡すことができません。
そのため、外部の知識ベースと検索と大規模言語モデルへの入力に適したサイズに分割することを想定し、最適な単位を見つけることが大切です。
4.メタデータの活用
メタデータを利用して検索結果の絞り込みや優先順位を付ける方法も効果的です。メタデータには作成日時やデータの種類、著者や部門、キーワードなどさまざまな情報があるため、利活用によって具体的なクエリにも対応できるようになります。
5.ハイブリッド検索の導入
ハイブリッド検索とは、従来のBN25などをはじめとしたキーワード検索とベクトル検索を組み合わせた検索方法のことです。ハイブリッド検索の導入によってそれぞれの検索方法の弱点を補填し、信頼性の高い検索が実現します。例えば固有名詞が質問に含まれる場合、ハイブリッド検索によって高精度な関連情報を取得できます。
6.GraphRAGの活用
GraphRAGとは、RAGの精度を向上させるための手法のことで、活用によって文脈に応じた高精度な情報検索を可能にします。これまでのRAGは、複雑な質問や段階的な推論を必要とする質問に難しさがありましたが、GraphRAGによって適切に対応できるようになります。
7.埋め込みモデルの選択・調整
RAGはユーザーからの質問と参照元データを数値ベクトルに埋め込み、そのベクトルの類似度に基づいて検索する特性があり、数値ベクトルに埋め込みを行うモデルの性能が高いほど検索の正確性が向上します。
例えば医療や法律、ITといった特定のジャンルに特化したデータでチューニングされた埋め込みモデルだと、専門用語や文脈を正確に捉えた上で信頼性の高いデータ生成が可能になるといったイメージです。特に組織内で利活用する生成AIを想定している場合であれば、埋め込みモデルの選択・調整はマスト作業ともいえるでしょう。
8.評価指標に基づいたフィードバックの継続
RAGの性能を客観的に表化できるよう、生成データに対する評価指標を洗い出しておきましょう。評価指標を明確にすることで全社に則した生成データであるかどうかが判断しやすくなります。評価指標には、下記の項目を盛り込むことをおすすめします。
|
項目 |
概要 |
|
精度 |
検索によって取得したコンテキストのなかにどのくらい関連性の高い情報が含まれているか |
|
再現率 |
回答に必要な情報がどれだけ検索されたコンテキストのなかに含まれているか |
|
忠実性 (ハルシネーションの度合い) |
生成データが与えられたコンテキストの内容に対してどれくらい忠実か |
|
関連性 |
生成データがユーザーの質問に対してどのくらい関連しているか |
これらの指標を元に定期測定・フィードバックを継続すれば、低いパフォーマンス部分を特定・改善しながら精度を上げることができます。
9.再ランキング処理を介した並び替え
再ランキング処理は、AIが初期検索で生成した候補データを再評価し、関連性の高いものから並べ直す作業です。再ランキング処理を介すことで質問に対して適切な情報を優先的に生成できるようになります。
例えば初期検索で取得したいくつかの候補が同スコアだった場合、質問のコンテキストとの一致度が高い情報から並べられるため、高精度な回答が生成されやすくなります。検索結果のノイズの削減につながるので、必要な情報に速やかに到達できます。
10.高度なRAGアーキテクチャの導入
RAGシステムを全体的に強化するため、高度なRAGアーキテクチャの導入もおすすめです。具体的には下表のようなものが一例として挙げられます。
|
項目 |
概要 |
|
Query Transformations |
・クエリの再構成あるいは拡張を通じて検索精度を高める手法 ・検索エンジンがユーザーの意図をより正確に理解できるようになり、関連性の高い情報を取得しやすくなる |
|
Self-RAG |
・大規模言語モデルが自己反省を通じて検索の必要性や取得したドキュメントの質を評価し、応答の正確性・信頼性を高める手法 ・検索結果のノイズを避けハルシネーションの減少に期待できる |
|
Corrective RAG(CRAG) |
・初期回答結果に対して追加の検索・修正を実施し、回答の正確性を高める手法 ・ユーザーの質問に対して信頼性の高い情報を提供できる |
|
Ensemble Retrieval |
・複数の検索モデルを組み合わし、総合的な検索結果を生成する手法 ・検索精度・網羅性の向上に期待できる |
生成AIをより組織的なもの、そして信頼性の高いものにするためにRAGは高い技術として注目を集めています。これらの手法を交えながら全社に有効な生成AIを生み出し、業務の効率化・最適化を実現させましょう。
RAGのメリット
ここからはRAGのメリットについて解説します。生成AIに対して、そして使用するユーザー側のそれぞれのメリットを見ていきましょう。
データの信頼性が向上する
生成AIが生成したデータには、まだまだハルシネーションが起こりやすいです。その欠点を補う技術がRAGであり、使用によって参照元の情報に基づいた回答を生成でき、出力データの正確性・信頼性向上を実現します。
容易に情報更新できる
従来の大規模言語モデルでは、最新の情報を反映させるためにモデルの再学習が必要としており、そのための時間やコストが増えやすいといった懸念がありました。RAGは外部の知識ベースを参照する特性があるため、知識ベースの更新のみで大規模言語モデルに鮮度の高い情報を取り込むことができます。
費用対効果に期待できる
大規模言語モデルをゼロから訓練する、あるいは特定のジャンルに備えた知識を取り込むためのチューニングをするためには多くのコストや時間を要します。しかしRAGによって既存ベースの大規模言語モデルを使いつつ外部データと連携するので、コストを抑えながら特定の用途に応じた生成AIを構築・運用できます。
回答の最適化につながる
RAGはユーザーが提示する質問に関する具体的な情報を外部から収集・取得し、その内容を大規模言語モデルに提供する特性があります。そのため、大規模言語モデルは質問の文脈を理解し、根拠に基づく回答が生成できるようになります。その結果、ユーザーにとって有用・有益となる回答の提供も増加します。
RAGの活用例
ここからはRAGの使用方法をより身近にイメージできるよう、具体的な活用例について解説します。
社内用AIチャットボット
RAGの一般的な活用例として社内用AIチャットボットが挙げられます。企業内の膨大なドキュメントを知識ベースとしてRAGと連携させることで、従業員からの質問に対し正確かつ最新情報を速やかに提供する環境が実現します。一例としては、新入社員のオンボーディングや部門間の情報共有などの効率化が期待できます。
カスタマーサポート
自社顧客から届く多様な問い合わせに対し、正確な回答を生成することも可能です。RAGはFAQをはじめ製品マニュアルやトラブルシューティングガイドに加え、過去のサポート履歴などから関連情報を取得できるので、顧客が求める答えを迅速に提供できます。
市場調査
RAGは検索エンジン上で公開されている市場レポートやWebメディアのコラム記事、ニュース記事や競合他社のプレスリリース記事など多くの情報を参照し、理想にほど近い分析結果を生成できます。分析結果に正確性が増すので、SNSやECサイトの運用に最新トレンドなどを盛り込んだアプローチなども可能になります。
情報収集・分析
RAGによって広範囲にわたるWeb情報のほか非公開情報の収集・取得も可能なため、特定のテーマに関する情報も効率的に集めながら要約・分析できるようになります。特定の分野に絞った大学や医療機関、IT企業など、限定的な情報を取得したいときこそRAGの使用によって効果的に取り組めるでしょう。
RAGにある6つの注意点
RAGの使用にあたっては以下6つの注意点に留意しましょう。
RAGでも解決できないことがある
RAGは生成AIにおける課題解決に有効な技術ですが、解決できないこともある点に注意しましょう。例えば、提示されたURLが存在しない場合や矛盾・事実とは異なる情報が参照元に含まれていた場合、RAGを使用しても正確な回答を生成することはできません。
また、医療や法律、ITなど限定的または専門的なデータを生成したい場合、これらに関する情報の収集・学習を経由しないとハルシネーションを招く恐れがあります。
収集データ・情報の質によって品質が変わる
RAGの回答品質は、収集したデータや情報の質によって大きく変わります。提供するデータがあいまいなものや誤解を与えるようなものであったり、事実とは異なる情報が含まれたりする場合、正確な情報を取得できないために回答の品質が下がります。
関連ワードを取りこぼすことがある
RAGを使った情報検索は、ユーザーからの質問と知識ベースとの関連性に基づいて行われるものです。しかし、完璧に収集し生成するわけではありません。限定的・専門的なジャンルの場合、関連ワードや文脈を正確に理解できないことがあります。
コストが掛かる・リソースを費やす
RAGの構築・運用にあたっては、初期導入コストだけでなくランニングコストも掛かります。例えば参照元データのデジタル化や運用に従事する外注費などが挙げられます。また、質問内容によっては従来のAIツールと比べて応答時間が長引くこともあり、速やかに情報を取得したいなどの顧客体験に影響が出る場合もあります。
メンテナンスが複雑
RAGの使用にあたっては、当然ながら適切なメンテナンスが欠かせません。大規模言語モデルをはじめ検索システムなどさまざまな要素で構成されているため、それぞれのバージョン管理やトラブルが発生した場合の原因特定、修正の実施などに時間がかかる場合があります。生成AIやRAGに精通した人材の確保・育成がなされていない場合、迅速なトラブル解決が難しくなります。
高いセキュリティが欠かせない
RAGで企業内の非公開情報や機密情報を取り扱う場合、情報の漏洩や不正アクセスリスクを避けるため、高いセキュリティ体制を構築する必要があります。例えば、参照元データへのアクセスは一定の従業員のみに限定する、データを暗号化する、監査ログを取得するなどの対策が必要です。
まとめ
生成AIの進化は目覚ましく、ビジネスにおける活用は不可欠な時代になりつつあります。しかし大規模言語モデルが抱えるハルシネーションや情報鮮度の問題は、実用化における大きな課題ですが、そこで注目されているのがRAGです。
RAGの導入には収集データ・情報の質による品質変動をはじめ、関連情報の取りこぼし、コストやリソースといった注意点も存在します。RAGの性能を最大限に引き出すためには、プロンプトエンジニアリングの最適化や継続的な評価と改善が不可欠です。
RAGを活用した生成AIの導入・運用を検討される際は、Peaceful Morningの「DX Boost」をぜひご活用ください。600万名超のプロ人材データベースから、貴社の課題や目的に最適なDX人材を即日でご提案できるため、スピード感を持ってRAGの導入・構築を進められます。


コメントを残す