
UiPathの活用を支援させていただく中、UiPath社が提供するドキュメント処理ツール「Document Understanding」について多くの企業からご質問いただきます。
RPAの活躍の場を広げるためにOCRの導入を検討される企業は多く、特にUiPathを使用している企業では、Document Understandingに期待する声も多いようです。
結論、UiPathを利用している企業にとって、Document Understandingは大変有用なソリューションとなりえます。
本記事では、気になる「利用コスト」の考え方と「ドキュメントの読取精度」についても解説します。
記事の最後では、「利用コストの計算」と「ドキュメントの読取精度の検証」を無償でお手伝いするご案内を用意しております。
「実際にウチの帳票に使えるの?結局いくらかかるの?」といった疑問に回答いたします。
ぜひご活用ください。
目次
Uipath Document Understandingとは
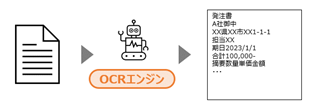
Document Understandingとは、UiPath社が提供するドキュメント処理ツールです。
この中にOCR機能が含まれており、紙やスキャン画像等のデータからテキストを抽出することができるようになっています。
RPA単体では、自動化できる業務はPC上の業務のみで、紙やスキャン画像を元に処理を行う業務は対象外となるか、一度手動でデータ入力を行うといった工夫が必要です。
ここにOCRを組み合わせ、スキャン画像からデータを抽出することで、紙やPDFデータを元にした業務の自動化が可能になります。
また、Document UnderstandingのOCR機能の多くは、RPA開発ツール(Studio/StudioX)上でOCR機能を実装します。
Document Understandingの特徴
Studioのみで処理を完結できる
Document Understandingの大きな特徴の1つは、RPA開発ツール(Studio/StudioX)上で開発できることです。
そのため、外部ツールとの連携なく手元のUiPath Studioですぐに開発・検証することができます。
また、通常のアクティビティの一つとして動作するため、対象ファイルの絞り込み等も容易に行うことができ、柔軟な開発が可能となります。
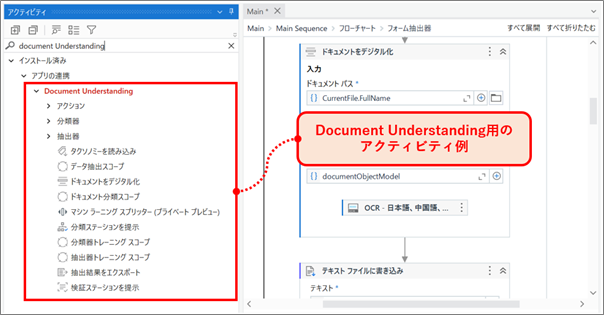
Document Understandingアクティビティ例
使用するOCRエンジンを選択できる
OCRのテキスト読取精度は、OCRエンジン(画像中に含まれるテキストをデジタル化するソフトウェア)に依存します。
多くのOCRツールは使用するOCRエンジンが指定されている一方、Document Understandingは複数のOCRエンジンから選択することができます。
UiPath社が提供するOCRエンジンのほか、Google社やMicrosoft社が提供するもの等を選択でき、読み込むドキュメントに応じて最適なものを検証・利用することができます。
なお、UiPath社が提供するOCRエンジンはDocument Understandingの購入により無償で使用できますが、他社のものを使用する場合、提供ベンダーから別途購入が必要となるものがあります。
レイアウトが異なる帳票に対応できる
OCRツールの多くは、ドキュメントのレイアウトが統一されていて、各項目の読取箇所が同一であることが前提になっています。
例えば発注書から合計金額を読み取りたいとき、その項目が発注書のどこにあるかが固定されていなくてはなりません。
一方、Document Understandingでは、様々なドキュメントを用いて学習させることで、レイアウトが異なっていても項目を読み取ることができるようになります。
また、開発段階で学習させるだけでなく、利用開始後にも継続的に再学習させ、精度を向上させていくことができます。
Document Understandingのドキュメント処理プロセス
ここで、Document Understandingがどのように動作するのか、その全体像を理解しましょう。
Document Understandingは次の5つのステップで、ドキュメント処理を行います。

ドキュメント処理プロセス(英語表記は公式の表現です。日本語表記は本記事用に一部変更しています)
①タクソノミーの読み込み
タクソノミーとはドキュメントの定義情報を指し、次のような情報を持っています。
- ドキュメントの種別 : 「③ドキュメントの分類」にて使用
- 各ドキュメントの読込箇所 : 「④項目抽出」にて使用
ここでは、後続の処理で使用するためにこれらの定義情報を読み込みます。
②デジタル化
OCRエンジン(画像中に含まれるテキストを認識するソフトウェア)を用いてデジタルデータに変換します。
ここではドキュメントの種別や抽出項目は関係なく、ドキュメント全体からテキスト情報等を抽出します。
UiPath社が提供するOCRエンジンのほか、Google社やMicrosoft社が提供するものを使用することも可能です。
なお、UiPathが提供するエンジンは無償で利用することができます。
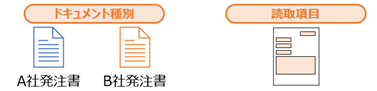
③ドキュメントの分類
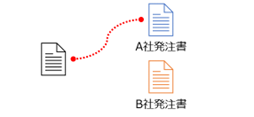
タクソノミーの定義情報をもとに、読み込んだドキュメントがどのドキュメントか分類します。
たとえばA社の発注書、B社の発注書といった具体的な種類に分けられます。
④項目抽出
社名、発注内容、数量、金額など読み取りたい各項目の値を抽出します。この作業も、タクソノミーとして事前に設定した抽出項目に基づいて行われます。

⑤エクスポート
抽出した情報を出力し、後続の処理で使用します。
これらのステップを経て、Document Understandingは複雑なドキュメントから重要な情報を抽出し、それをRPAプロセスに組み込むことが可能となります。
読取精度の検証結果
UiPath社の日本語対応OCRエンジン(CJK-OCR)を用いて読取精度を検証してみました。
実際の読取精度はスキャンの品質等様々な要因によって異なるため、参考程度に見てください。
また、前述の通りCJK-OCR以外のOCRエンジンを選択することもできるため、精度が低くなるものについては他のOCRエンジンを検討することも重要です。
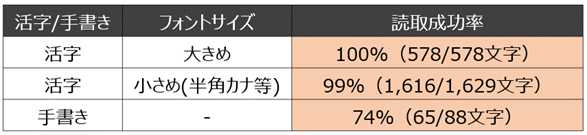
今回の検証では、「CJK-OCRでの読取は、活字の読取精度は非常に高い。一方手書きは日本語の読取精度が低く、用途が限られる」という結果になりました。

活字であれば、目視でも判断しづらい 「 バ 」 と 「 パ 」などもしっかり読み取ることができます。
これは、他社のOCRでの検証結果と比較しても非常に高い精度です。
手書きについては、正しく読み取れない箇所が多く、データ変換による対処も厳しいと感じました。
日本語の手書き読取が必要な場合は、CJK-OCR以外のOCRエンジンも含め検証することを推奨します。
一方、英数字や✓マークの読取精度は非常に高かったため、「コード」や「現場チェックシート」の読取等の用途では、手書きの読取が可能と考えられます。
利用コストの考え方
AI Unitsとは
AI Unitsとは、Document UnderstandingなどUiPathのAI製品を利用するためのライセンスです。
AI Unitsは利用量に応じて消費される消費型のライセンスであるため、どの程度利用するか計算し、必要な量を購入する必要があります。
Document Understandingでは、「③ドキュメントの分類」と「④項目抽出」の際にAI Unitsを消費します。
AI Unitsライセンス数の確認方法
まずは、現状に付与されているAI Unitsを確認しましょう。
ここでは、Automation CloudにてAI Unitsのライセンス数の確認方法を紹介します。
※一部ライセンスではAI Unitsの表示がない場合があります。その場合は契約時の資料を参照するか、UiPath のカスタマーサポートへご確認ください。
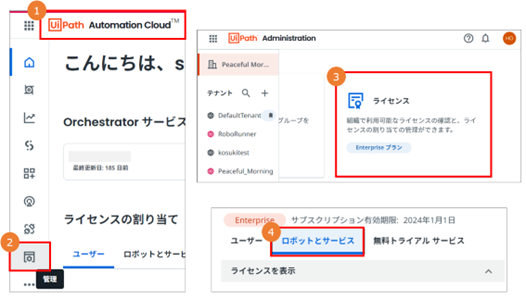
①Automation Cloud(https://cloud.uipath.com/)へアクセス
②「管理」をクリックし、UiPath Administration を開く
③「ライセンス」をクリック
④「ロボットとサービス」をクリック
AI Unitsが付与されている場合、次のようなAI Unitsの項目が表示されます。
この場合、60K(60,000)AI Unitsを持っている状態です。

Document UnderstandingによるAI Units消費量
先ほど紹介したドキュメント処理プロセスのうち、「③ドキュメントの分類」「④項目抽出」でAI Unitsを消費します。
ここでは、各プロセスでのAI Units消費量の考え方を解説します。
詳細は公式ドキュメント(Automation Cloud のDocument Understanding 使用状況の測定と請求ロジック)を参照して下さい。
③ドキュメントの分類
ドキュメント分類については、多くの場合無償で使用することができます。
まず、ドキュメント分類に使用する分類器には「キーワード分類器」「インテリジェント キーワード分類器」「ML 分類器」の3種類がありますが、このうち「キーワード分類器」は無償で使用できます。
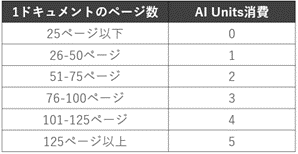
「インテリジェント キーワード分類器」「ML 分類器」については、1ドキュメントのページ数によってAI Units消費量が決まります。
ページ数ごとの消費量は次の通りですが、1ドキュメント25ページ以下の場合は無償となるため、多くのケースでは無償で使用できます。
④項目抽出
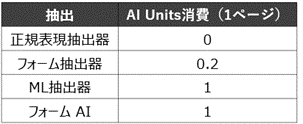
項目抽出は、1ページごとにAI Unitsが消費されます。
次の表の通り使用する抽出器により1ページ当たりの消費量が異なります。
レイアウトが固定されていることを前提とする「フォーム抽出器」と、レイアウトの変動に対応する「ML抽出器」「フォームAI」で消費量が異なっています。
なお、「正規表現抽出器」は名前の通りAIではなく正規表現を用いて抽出するため、AI Unitsは消費されません。
利用ケースごとのAI Units試算
上記の考え方に基づき、ドキュメントの処理ケースに対して、どの程度のAI Unitsが必要となるか試算してみましょう。
実際の処理枚数に対し、開発・テスト用に10%ほど余裕をもつことを推奨されていますので、これを考慮して算出していきます。
■ケース1

- ドキュメント分類
「インテリジェント キーワード分類器」を利用
→ 25ページ以下のため無償 - 項目抽出
レイアウトはほぼ固定されているため、「フォーム抽出器(0.2AI Units)」を利用
→ 1,000枚/年× 3ページ × 0.2AI Units = 600AI Units
【試算結果】(0AI Units + 600AI Units) × 110%(テスト用) = 660AI Units
■ケース2

- ドキュメント分類
「インテリジェント キーワード分類器」を利用
→ 5,000枚 × 1AI Units(30枚の場合の消費量) = 5,000AI Units - 項目抽出
レイアウトが異なるため、「フォームAI(1AI Units)」を利用
→ 5,000枚/年× 30ページ × 1AI Units = 150,000AI Units
【試算結果】 (5,000AI Units + 150,000AI Units) × 110%(テスト用) = 170,500AI Units


コメントを残す